这几天在学习Cuda Mode, 只之前听人说这是最合适入门Cuda的网课。但是听完了之后,我的结论是,这门课里的很多内容并不适合初学者,适合有一定并行学习基础的人。如果是还没接触过Cuda的学生的话,建议还是从斯坦福的CS149开始学习。我之前听过斯坦福的CS149,把里面的大作业都跟下来了,也算是有一点并行计算的基础;只是当时很多内容没有深究,看看网课就过去了,所以了解的不深。这门Cuda Mode更适合作为一门研究生课,请了很多业界大佬来给大家讲讲目前并行计算最关注的方向是哪些。这个系列也就是我的学习笔记,欢迎大家多多交流。阅读本文之前,读者应该需要有一些Cuda编程基础。如果没有可以阅读Nv的官方手册、看CS149的视频,或者图省事看看这篇知乎。
这一次的主题是Reduction。我个人认为这个主题相较于矩阵乘法GEMM更适合作为Cuda入门的第一个项目。因为Reduction的实现相较于GEMM更简单,且Reduction在实际应用中也足够广泛。本次笔记会以英伟达Mark Harris的Slides作结合,结合Github上前任基于Slides实现的代码和结合Cuda Mode Lecture 9的内容,来自己实现一个从0到1的Reduction。
Problem Definition - What is Reduction
如果用CPU来实现Reduction,只需要一个For循环即可,如下面代码所示。下面代码也是验证我们GPU代码是否正确的Benchmark。本次我们只讨论求和,因为可以很轻易的替换成其他运算(例如, 求最大值或是求最小值),本次我们的目的也不是写一个足够通用的函数。
1
2
3
4
5
def reduction(op: Function(Item, Item), X: List[Item]) -> Item:
y = I
for x in X:
y = op(x, I)
return y
在描述完这个问题之后,我们就基本可以判断出这个程序是一个很典型的memory-bound的函数,因为它的arithmetic intensity太低了。所以衡量我们实现Kernel的指标应该是Bandwidth而不是FLOPS。
Version 1: Naive Implementation
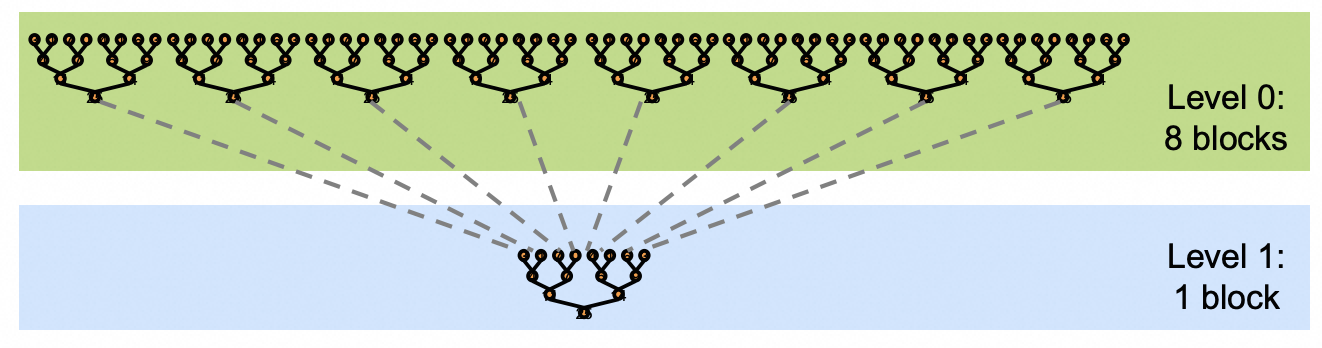
一个最朴素的想法是通过Tree的方式,让每一个thread处理一个元素,如下图所示。随着输入的扩大,这样的做法会遇到一个问题,每一个block里最大thread的数量是有限的,为了处理更多的元素我们势必要引入多个thread block;这个Tree的实现是需要在所有thread之间引入synchronize的,但是cuda里是没有global synchronize的。为了解决这个问题,Cuda Mode里讲师提出的解决方案是atomicAdd; Mark Harris提出的解决方案是launch多次Kernel,将Kernel Launch作为一个Global synchronize的方式。也就是下面的图二。不管最后性能如何,这两种思路都值得大家借鉴,至少这两个思路从正确性的角度来说都是没有问题的。
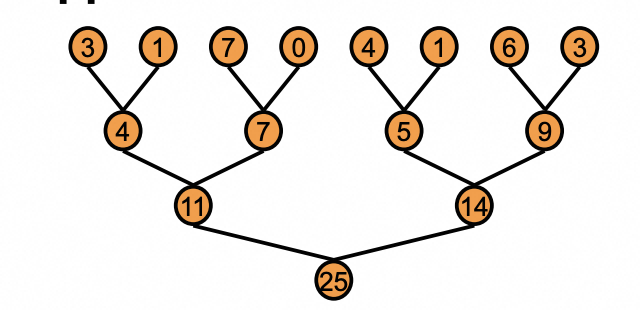
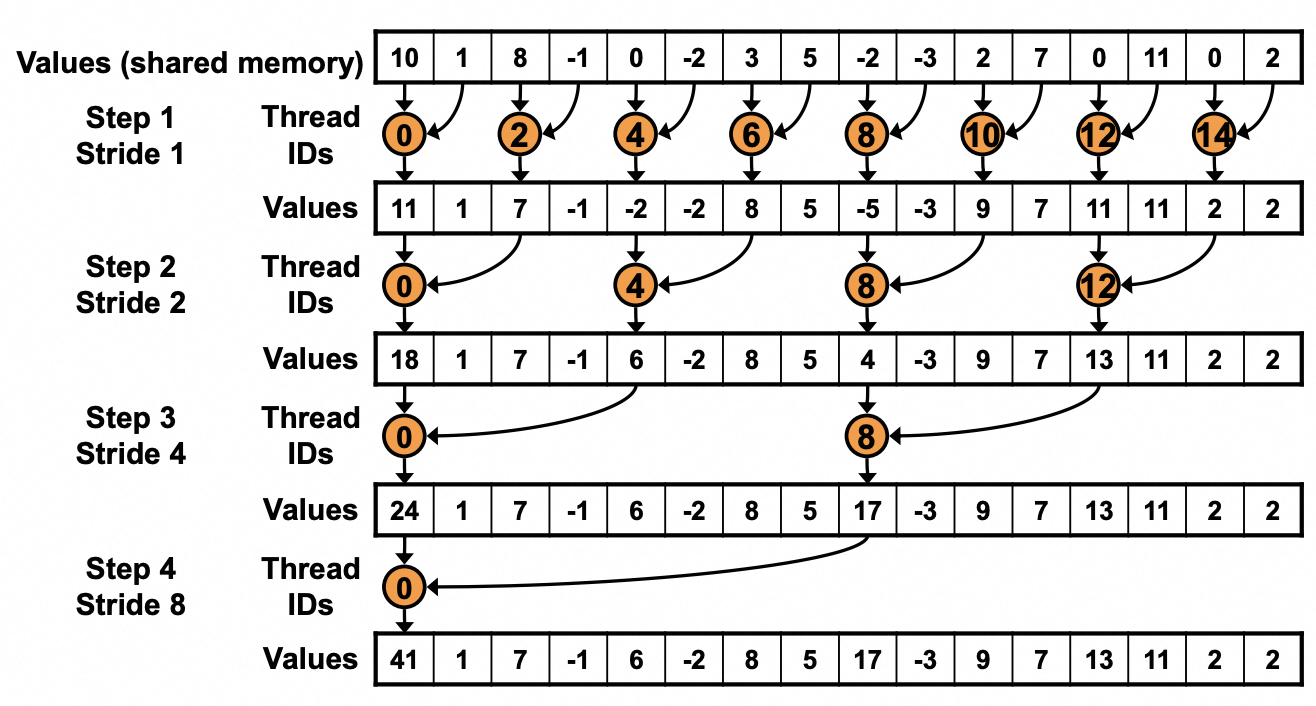
下面来讲讲具体实现,伪代码如下图所示;真实Cuda代码如下图所示。直接阅读代码会有点懵逼,结合图就比较清晰。图里明确说明了每一个迭代,哪些thread需要干哪些事情。
在这个代码实现里,每次只有2的幂次方的倍数的 thread 是active的,那些threadId 是奇数的 thread 在循环里是不做事情的。在GPU编程模型里,我们最希望一个warp里所有的thread都做一样的事情,因此 if else语句是很低效的。因此我们第一个优化目标就是图里那一段会导致thread之间divergent的代码。

Version 2: Interleaved Addressing
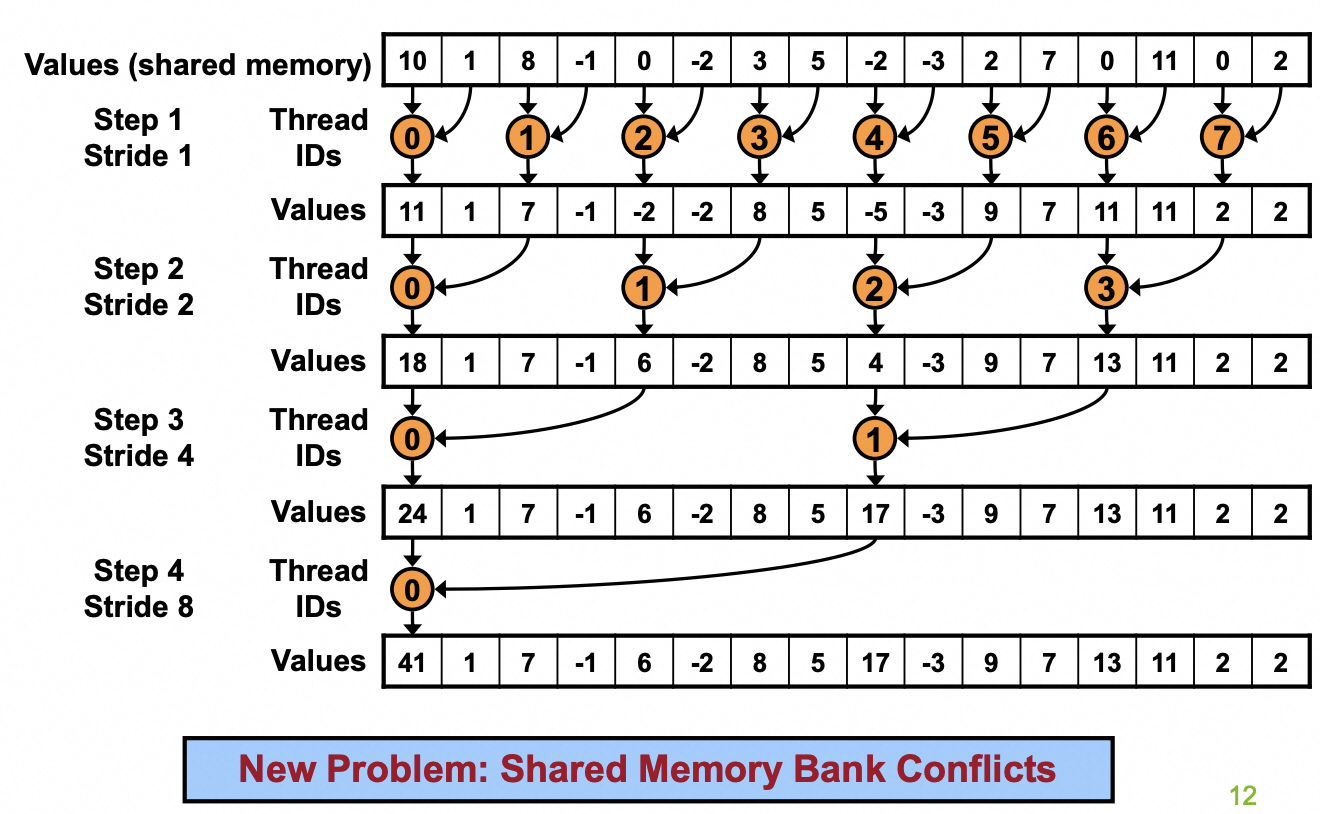
为了解决这个问题,我们可以用下面这张图,让每次”干事情”的thread都尽可能集中到一个warp里。具体代码也只需要做很少的改动。
在改完代码之后,重新审视,不难发现,每个thread去访问的Shared memory里的元素有相同的bank id,因此在sdata[index] 这一行必然会遇到bank conflict。关于什么是bank id可以参考这篇博客。

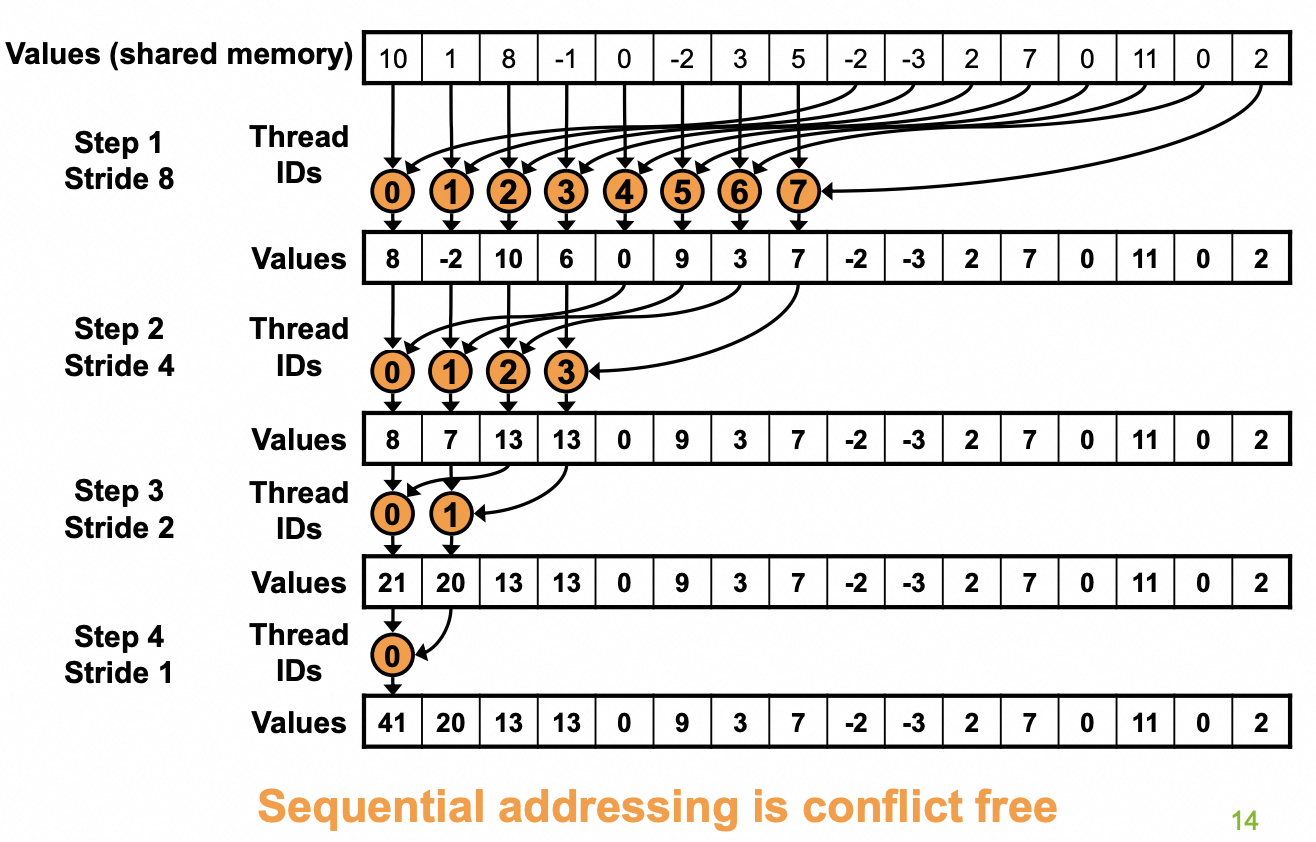
Version 3: Sequential Addressing
解决bank conflict的办法就是Sequential Addressing,也就是保证每个thread访问的数据有不同的bank id即可。为此我们再调整一下Tree,保证每个warp访问的数据也是彼此相邻的。

Version 4: First Add During Load
Version 3里的For Loop有一个问题: 哪怕是第一个迭代,也有一半的thread是idle的。这一半的thread只是load了一个data就结束了工作。这就有点暴殄天物了。为了优化这第一个迭代,我们可以一次load两个数据。这种优化思路也被称为Coarsen。

Version 5 & 6: Unroll
我们来测一下目前为止的带宽。我们的数据量为512M,数据类型为int,具体消息大小也就是2GB;测试环境是A100,理论带宽为1555GB/s。测试的结果如下:
1
2
3
4
5
6
CPU time: 1.65679 s, CPU Memory Bandwidth: 1.29617GB/s
[reduce0]GPU time: 0.015917 s, Memory Bandwidth: 134.918GB/s
[reduce1]GPU time: 0.008949 s, Memory Bandwidth: 239.969GB/s
[reduce2]GPU time: 0.007367 s, Memory Bandwidth: 291.5GB/s
[reduce3]GPU time: 0.003993 s, Memory Bandwidth: 537.812GB/s
[reduce4]GPU time: 0.003992 s, Memory Bandwidth: 537.947GB/s
可以看到,距离理论带宽还是差距。这个时候我们就要考虑并行策略里最常见的杀器: Unroll Loops。unroll loop可以优化 instruction overhead;因为在循环里,我们会引入一些辅助指令(Ancillary instructions, 也就是除了load、store、arithmetic for the core computation之外的指令)。最典型的是__syncthreads; 另外的则是循环里s > 0和s>>=1这些语句。通过unroll我们可以将这些指令消除。
第一个要消除的是__syncthreads,因为通常来说,synchronize的代价是较大的。在A100里,一个warp有32个thread,这32个thread的行为就根本不需要synchronize了,他们天然就是完全一致的。因此我们如下调整代码。这里值得注意的是sdata里的 volatile 前缀,这是为了保证数据别被cache在寄存器里,每次都要直接写回到Shared Memory里。

第二个要消除的是Loop里的其他辅助指令。如果我们从一开始就知道每个block有多少个thread,那我们就可以完全不需要Loop。非常幸运的是,我们是可以知道的。首先我们知道A100一个thread block 最多有2048个thread,其次我们可以通过template,将blockSize作为一个常量传入。那么如果我们blockSize比较小的时候,循环次数也会跟着变小。无需多说,代码如下。红色部分的代码可以交给编译器去优化,因为blockSize是编译时期就已经确定的常量。

Version 7: algorithm cascading - 调参
我们来分析一下整个算法的时间复杂度,并试着从算法层面进一步优化。假设我们的input规模是N,我们有P个thread。
-
最长的一个thread需要执行 O(log N) 步,这是被那个For循环决定的,也就是 Step Complexity 是 O(log N)。
-
所有的thread加起来总共需要执行 N-1 个Operation,也就是 Work Complexity 在至少是 O(N). 计算过程如下。但是实际上,我们会Launch O(N)个thread,每个thread会执行 O(log N) step,总的cost是O(N log N)。
- 如果我们 Launch O(N/log N) thread,每个thread需要load O(log N)个Item,然后再进行 O(log N)次For Loop,这样总的时间复杂度就从 O(N log N) 降为 O(N)。这个优化被称为
algorithm cascading。改动如下

实验分析
下面是我再A100机器上做的实验,实验代码参考我的代码仓库里reduce目录下的代码。下面 reduce7 下划线之后的数字就是每个thread应该load次Item(每次load 2个item,详见代码实现);当N=(1«29)时,理论最优解应该就是29/2,因此实际的最优解是16。并且最终的带宽已经非常接近理论上限1555GB/s了。
同时,利用这段代码, 我还在A100上进行了最终的实现和Pytorch的差异。我发现如果只跑10次Reduction,Pytorch要花40ms,我的实现只需要29ms;但如果是100ms, pytorch要花245ms, 我的实现要花261ms。这里我认为是Pytorch在Malloc上做了优化,毕竟每次都Alloc新的显存太不优雅了。torch.compile则非常的不靠谱,不知道为啥性能很低。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
CPU time: 1.65679 s, CPU Memory Bandwidth: 1.29617GB/s
[reduce0]GPU time: 0.015917 s, Memory Bandwidth: 134.918GB/s
[reduce1]GPU time: 0.008949 s, Memory Bandwidth: 239.969GB/s
[reduce2]GPU time: 0.007367 s, Memory Bandwidth: 291.5GB/s
[reduce3]GPU time: 0.003993 s, Memory Bandwidth: 537.812GB/s
[reduce4]GPU time: 0.003992 s, Memory Bandwidth: 537.947GB/s
[reduce5]GPU time: 0.002918 s, Memory Bandwidth: 735.944GB/s
[reduce6]GPU time: 0.002688 s, Memory Bandwidth: 798.915GB/s
[reduce7_1]GPU time: 0.002664 s, Memory Bandwidth: 806.112GB/s
[reduce7_2]GPU time: 0.001888 s, Memory Bandwidth: 1137.44GB/s
[reduce7_4]GPU time: 0.00158 s, Memory Bandwidth: 1359.17GB/s
[reduce7_8]GPU time: 0.001482 s, Memory Bandwidth: 1449.04GB/s
[reduce7_16]GPU time: 0.001477 s, Memory Bandwidth: 1453.95GB/s
[reduce7_32]GPU time: 0.001491 s, Memory Bandwidth: 1440.3GB/s
[reduce7_64]GPU time: 0.001507 s, Memory Bandwidth: 1425.01GB/s
[reduce7_128]GPU time: 0.001498 s, Memory Bandwidth: 1433.57GB/s
[reduce7_256]GPU time: 0.001515 s, Memory Bandwidth: 1417.48GB/s
[reduce7_512]GPU time: 0.001637 s, Memory Bandwidth: 1311.84GB/s
[reduce7_1024]GPU time: 0.001959 s, Memory Bandwidth: 1096.21GB/s
