Background
在目前训练/推理的各个场景里,Attention层的并行策略和MoE层的并行策略是不一样的。这个已经逐渐成为了一种趋势,因为MoE层里有EP这个额外的并行策略考虑。目前Sglang的代码演进的很快,如果只看代码会发现可能过几天就变了;理解一些high level的概念之后再去看代码,会发现都是一脉相承,会更好的理解代码。
本文重点看Sglang里dp attention这个概念,试图回答以下问题: 什么是 dp attention,为什么dp attention能带来性能提升,未来有什么演进的方向。欢迎大家多多交流。
在正式介绍之前,引用SGLang v0.4 blog里的一张图,介绍一些代码里的一些参数以及与之对应的概念。
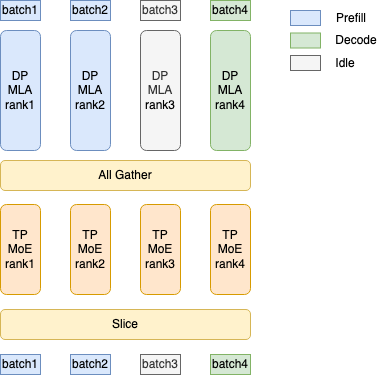
-
tp_size: 这个其实说的是World-Size。上图可以理解成tp_size=4 -
dp_size: 等价于attention_dp_size,代表attention层会同时处理多少个micro-batch。上图中dp_size=4 -
attn_tp_size: 其值等于tp_size//dp_size,代表Attention层的tp-size,上图中attn_tp_size=1
DP Attention
简单做一个概述:dp-attention 是一种将Attention层并行策略和MLP层并行策略分离的策略,Attention层的的tp-size引入了attn_tp_size 来单独描述。在下面的代码例子里,首先介绍非DeepEP模式下的MLP Layer实现,在代码里对应FusedMoE和EPMoE两个实现,这两个实现对于MLP层Input的要求是一样的;然后介绍DeepEP实现下DP Attention的特点。
-
“为什么XXXLayer的输入是一个micro-batch”类似的不在这篇文章里叙述。这就需要讲解不同Layer的代码,能讲很多。
-
下面画图里的xxx-mode 可以先忽略,这个目前是代码里做了很好的抽象,我会在最后对这部分做一个补充。
EP-MoE & FusedMoE

-
DecoderLayer的输入是一个micro-batch,和AttentionLayer的输入一致,因此不需要通信
-
Attention层的输出是一个micro-batch,MLP层的输入是所有micro-batch完整Feature。这里主要要先在attn-tp group内做一个all-reduce(tp的要求,保证Feature的完整),然后再在attn-dp group内做一个all-gather;在sglang的实现里,tp = attn-tp * dp,所以选择直接在tp group内做一次all-reduce。关于这个选择是否合理放在后面讨论,目前知道就是这么做的。
-
MLP层内部会有一个tp_group的all_reduce,保证MLP层输出的feature不是一个shard
-
MLP层(EP-MoE模式和FusedMoE模式)输出则是所有micro-batch 完整Feature,DecoderLayer的输出是一个micro-batch Feature,因此最后会有取split的操作。不需要通信
sglang的伪代码如下
1
2
3
4
5
6
7
8
9
10
def forward_normal(hidden_states):
attn_input, residual = hidden_states, hidden_states
attn_output = self_attn(attn_input) # (mbs, h) -> (mbs, h)
gathered_buffer.fill(0)
gathered_buffer[dp_start:dp_end] = attn_output
hidden_states = all_reduce(gathered_buffer, tp_group)
residual = hidden_states[dp_start:dp_end]
mlp_input = layernorm(hidden_states)
mlp_output = mlp(mlp_input) # (mbs * dp, h) -> (mbs * dp, h)
return mlp_output[dp_start:dp_end]
上面的代码是相对比较完整的代码。其中一个all_reduce被封装在了mlp内部。只看这段代码,当dp=1时,gathered-buffer其实就是attn-output, 自然就不需要fill和copy的逻辑;按理说mlp-output也就不需要进行copy
下面对伪代码中出现的all-reduce逻辑进行一个分析(对应上面伪代码中4-7行,对应sglang源码里_gather_hidden_states这个函数)。下面这段代码其实从attn-output转化为mlp_input更自然的版本
1
2
3
attn_output = all_reduce(attn_output, attn_tp_group)
residual = attn_output
hidden_states = all_gather(attn_output, dp_group)
也就是说,目前sglang的实现用all_reduce(tp_group) + slice(attn_dp_rank)替换了all_reduce(attn_tp_group) + all_gather(dp_group)。这么做的点笔者认为是在一个batch里,不同的micro-batch的大小可能是不一样的(参考最上面的图),如果是这样就没法用all_gather,因为all_gather要求所有input的大小是一致的。但是实际上这里的通信量是被放大了的。
下面就是笔者个人的观点:只从通信量的角度来看,这部分代码是有优化空间的。额外的工作量是实现一个custom_all_gather来替换custom_all_reduce。但是在目前DeepEP出现的场景下,通信模式就不一样了,具体是否需要优化这部分代码还是要看模型的具体需求。
DeepEP

-
DecoderLayer的输入是micro-batch在attn-tp group里的一个Shard,AttentionLayer的输入完整的micro-batch,因此需要一个attn-tp group之间的all-gather通信
-
Attention层的输出是每个micro-batch Feature(但是feature不完整),MLP层的输入是micro-batch Feature在attn-tp group里的一个Shard,因此在attn-tp group之间进行了reduce-scatter通信。对比上面,这里其实将attn-tp的all-reduce拆成了all-gather和reduce-scatter,本质上是输入/输出的要求变了
-
MLP层内部会有一个ep group的dispatch和combine,这里ep group就是tp group
-
MLP层输出则是micro-batch Feature在attn-tp group里的一个Shard,和DecoderLayer的输出一致,不需要通信
sglang的伪代码如下
1
2
3
4
5
6
7
8
def forward_deepep(hidden_states):
hidden_states, residual = layernorm(hidden_states), hidden_states
attn_input = all_gather(hidden_states, attn_tp_group)
attn_output = self_attn(attn_input) # (mbs, h) -> (mbs, h)
hidden_states = reduce_scatter(attn_output, attn_tp_group)
mlp_input, residual = layernorm(hidden_states, residual)
mlp_output = mlp(mlp_input) # (mbs//attn_tp, h) -> (mbs//attn_tp, h)
return mlp_output
X-Mode in Sglang
在Sglang的代码里,引入了LayerScatterModes对不同的切分状态做了不同的划分,并根据前后的状态将所有的通信都封装在LayerCommunicator这个类里。下面是我个人对各个变量的理解
-
Scatter的含义是,变量被切分成了tp份,已经不能再切了 -
TP_ATTN_FULL的含义是,变量被切分成了dp份,还能按照attn_tp这个维度切分 -
FULL的含义是,变量没有被切分,还能按照tp这个维度切分
下面来举一个例子,如果input_mode == SCATTERED and output_mode == TP_ATTN_FULL,那么就应该在attn_tp这个维度做一个all_gather;在CommunicateSimpleFn.get_fn里,可以看到_scattered_to_tp_attn_full这个函数确实是这个逻辑。
Size of Attn-TP
现在已经初步介绍了DP-Attention,可是为什么dp-attention能带来性能提升呢?这个问题可以换一个问法,attn-tp的大小应该设置成多大呢?当attn-tp size等于tp size时,dp=1,相当于关闭了dp-attention;而与之对应的另一个极端是,dp=tp,相当于attention层完全不用tp。 当控制变量的时候,应该控制 mbs * dp 不变,那么dp变大的一个好处就是,attn-input 的大小变小了,这就意味着kv-cache的大小变小了。这是dp-attention一个重要的优势。 在DeepEP的setting下,设置dp=tp的另一个比较明显的好处是,可以避免all_gather和reduce_scatter。考虑到目前all_gather和reduce_scatter都是NCCL的实现,效率很低,可以估计dp=tp会有巨大的优势。
在EPMoE和FusedMoE的setting。由于实现的原因,dp的大小并不会影响通信次数和通信量,那么此时就应当考虑并行策略对计算的影响了,切Input和切weight都可以减半计算量,但是不同的切法会导致tensor的shape不一致,进而影响计算效率。事实上,在Batch较小的场景下,矩阵乘法是访存密集型的,其耗时会被weight的大小主导,这个时候切weight的TP就会更高效,而DP-Attention在这个场景下是不占优势的。事实上,DP-Attention在通信函数里还引入了额外的开销(例如fill_(0)和memcpy)。
如果使用bench_one_batch来进行实验,那么DP-Attention对于减少KVCache的优势就消失了,overhead会暴露出来。所以在EPMoE和FusedMoE场景下是否要使用DP-Attention还是要实测一下(当然真要追求极致性能还是得看DeepEP)。如果在H100环境下用下面这个测试命令测试QWen3-30B-A3B的吞吐,不开DP-Attention的吞吐(中位数)是4091,开了DP-Attention的吞吐(中位数)是3185。
下面是实验代码,感兴趣(有机器)的小伙伴可以自行实验
1
2
python3 -m sglang.bench_one_batch --model Qwen/Qwen3-30B-A3B --batch 32 --input-len 256 --output-len 32 --tp 4
python3 -m sglang.bench_one_batch --model Qwen/Qwen3-30B-A3B --batch 32 --input-len 256 --output-len 32 --tp 4 --dp 4 --enable-dp-attention
