序言
之前看过翁家翌大佬的一个访谈,里面提到”教会做工程的人算法,比教会做算法的人工程要容易得多”。但我觉得这多少有些幸存者偏差——他自己天资聪慧,所以觉得有些东西”似乎”没那么难。作为一个工程师,我还是觉得算法比工程难得多。但无奈的是,我现在发现如果不去了解一些算法背后的 idea,做起工程来会很被动——知其然而不知其所以然,遇到问题就容易束手无策。
最近在公司正好在做 image/video generation 相关的工作,于是找了一些 diffusion 的学习资料,试着从工程师的视角来理解这些算法。写这个系列笔记的目的,是帮助自己对 training framework 和 inference framework 有更深入的理解,同时会尽可能把理论和代码联系起来。我主要会以 diffusers 和 sglang-diffusion 两个 repo 作为例子。
当我开始真正接触 Diffusion 模型后,发现 Yang Song 的博客 Generative Modeling by Estimating Gradients of the Data Distribution 是绕不开的必读之作。兴致冲冲地去读了之后,发现完全看不懂。后来很开心地发现苏剑林老师写过一个系列专门讲解这个主题,但我依然读不太懂。说一下我的背景:本科没上过常微分方程,master 毕业,有两年 AI Infra 的工程经验,遥远的学生时代留下过一丢丢数学基础。在看了大量资料之后,我发现 MIT 6.S184: Introduction to Flow Matching and Diffusion Models 是最适合我的入门材料——循序渐进且不过度劝退。这个系列会跟着这门课的脉络来梳理 diffusion 相关的理论知识。我的终极目标是有朝一日能真正读懂 Yang Song 的那篇博客。
Diffusion Model - Theory
Generation as Sampling
我们所熟知的”生成”,本质上可以理解成从一个概率分布中采样(sampling)。这正是 MIT 6.S184 开篇提出的核心思想:Generation as Sampling。
举个例子:假设 prompt 是”生成一张狗的图片”,显然不存在唯一一张”最好的”狗的图片,但可以通过某种标准来判断生成结果的好坏——比如让人看一眼,觉得像不像一条狗。可以认为所有潜在的、满足该 prompt 的图片都服从某个概率分布 $p_{data}$。生成模型要做的事情,就是学会从 $p_{data}$ 中采样。
关于符号约定
需要特别说明的是,不同论文和课程对 $x_0$ 的定义是不同的。在 MIT 6.S184 中:
- $X_0 \sim p_{\text{init}}$ 代表噪声(起点),$X_1 \sim p_{\text{data}}$ 代表数据(终点)
- 时间从 $t=0$(纯噪声)流向 $t=1$(干净数据)
但在很多早期论文(如 DDPM)以及实际代码中,符号定义恰好相反:变量 x_0 代表 denoise 之后的”干净”结果。本文采用后者,因为这与我阅读的大部分代码一致:
- $(x_t)_{0 \leq t \leq 1}$ 代表某个样本在变化过程中的轨迹
- $x_0 \sim p_{data}$ 代表终点,满足未知的数据分布,含义为图像/视频数据
- $z = x_1 \sim p_{init}$ 代表起点,满足已知的初始分布(通常是标准高斯分布 $\mathcal{N}(0, I)$),含义为纯噪声
- $z \sim p_{data}(\cdot \mid y)$ 代表条件生成(Conditional Generation),其中 $y$ 为 prompt 等条件信息
前向 Diffusion 过程
理解了上面的符号之后,”前向 diffusion”就很直观了:给定一张图片或一段视频(即 $x_0 \sim p_{data}$),通过逐步往里面添加噪声,将数据分布 $p_{data}$ 逐渐转变为简单的初始分布 $p_{init}$。在苏剑林老师的这篇博客中提到过,代码里常见的 num_train_timesteps=1000 是因为:经过 1000 步加噪之后,结果在 $e^{-5}$ 的误差范围内就和纯噪声没有区别了。
而 Diffusion 模型需要学习的是这个过程的逆过程:从已知的初始分布 $p_{init}$ 出发,逐步变换到数据分布 $p_{data}$。每一个随机噪声点不断演化、最终变成图像/视频的过程,就是一条轨迹(trajectory)。不同的模型对这条轨迹有不同的数学建模方式,下面分别介绍。
Flow Model & ODE
Flow Model 将生成过程建模为一个常微分方程(ODE)的解。一个 flow model 由一个向量场(vector field) $u$ 定义,轨迹 $(x_t)$ 满足如下 ODE:
\[\frac{\mathrm{d}x_t}{\mathrm{d}t} = u_t^\theta(x_t)\]其中 $u_t^\theta$ 是一个由神经网络参数化的向量场。直观理解:在每个时刻 $t$ 和每个位置 $x$,向量场 $u_t^\theta(x)$ 给出了一个”速度”,告诉样本应该往哪个方向移动。讲义中特别强调了一点:虽然叫做 flow model,但神经网络参数化的是向量场(vector field),而不是 flow 本身。
关于这个 ODE,有几件事需要注意:
关于解的存在与唯一性 只要向量场 $u$ 连续可微且导数有界,ODE 就有唯一解。在实践中,我们用神经网络来参数化 $u_t^\theta(x)$,而神经网络天然可导且导数有界,所以这个条件几乎总是满足的。这是个好消息——意味着理论解总是存在且唯一的,就看模型能拟合的多好了。
关于显式求解 假设存在一个万能的求解器,能够直接计算出 ODE 对应的 flow $\psi(x_1, t)$,那么轨迹上任意一点都可以通过 $x_t = \psi(x_1, t)$ 直接得到。对于生成任务,我们真正关心的只是终点 $x_0 = \psi(x_1, 0)$——最终生成的图片或视频。如果能显式求解,就可以一步到位。讲义中给了一个可以显式求解的例子:对于线性向量场 $u_t(x) = -\theta x$($\theta > 0$),其解为 $\psi_t(x_0) = \exp(-\theta t) \, x_0$,所有点会指数衰减地收敛到原点。
关于数值近似求解 然而绝大多数情况下,ODE 的解无法显式写出,只能通过数值方法来近似求解。最简单也最直观的是 Euler Method:
\[X_{t+h} = X_t + h \, u_t^\theta(X_t), \quad \text{where} \ h = -n^{-1} < 0\]含义很朴素:每一步沿当前位置的向量场方向走一小步。除此之外还有 Heun’s method 等高阶方法——阶数越高,精度越好,但所需的计算量(即神经网络的前向调用次数)也越大。
从工程视角来看,求解这个 ODE 就等价于做 inference/generation:给定一个从 $p_{init}$ 采样的随机噪声点 $X_1$,通过反复调用神经网络 $u_t^\theta$ 来迭代更新位置,最终得到生成的图片 $X_0$。
Diffusion Model & SDE
Flow Model 的轨迹是确定性的——给定相同的起点,永远得到相同的终点。Diffusion Model 则在此基础上引入了随机性,将 ODE 扩展为随机微分方程(SDE):
\[\mathrm{d}x_t = u_t(x_t)\,\mathrm{d}t + \sigma_t\,\mathrm{d}W_t\]这里额外引入的 $W_t$ 是一个布朗运动(Brownian Motion),也叫 Wiener 过程。可以把它理解成一个”连续版的随机游走”,具有以下性质:
- $W_0 = 0$
- 增量服从高斯分布:$W_t - W_s \sim \mathcal{N}(0,(t-s) I_d)$,$\forall \, 0 \leq s < t$
- 不同时间段的增量彼此独立:$\forall \, 0 \leq t_0 < t_1 < \cdots < t_n = 1$,$W_{t_1} - W_{t_0}, \ldots, W_{t_n} - W_{t_{n-1}}$ 相互独立
- 可以通过 $W_{t+h} = W_t + \sqrt{h}\,\epsilon_t$,$\epsilon_t \sim \mathcal{N}(0, I_d)$ 来离散模拟
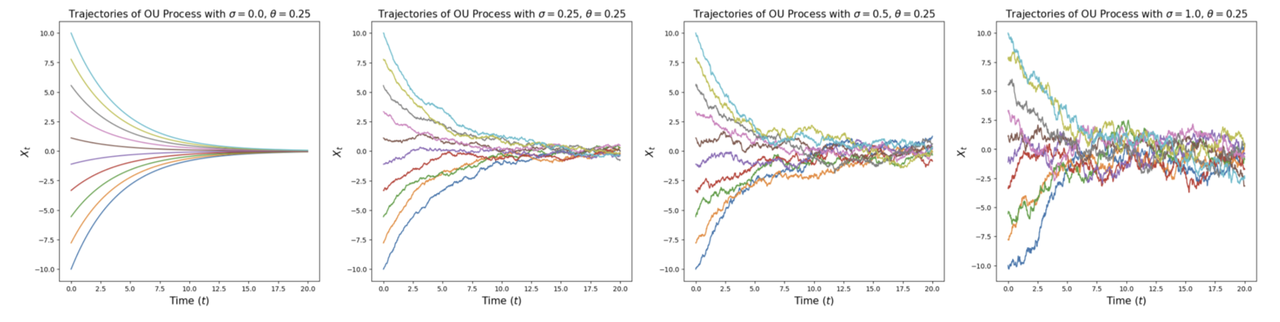
关于扩散系数 $\sigma_t$ 的直观 讲义中用 Ornstein-Uhlenbeck(OU)过程的例子做了很好的可视化:当 $u_t(x) = -\theta x$ 且 $\sigma_t = \sigma$ 为常量时,$\sigma = 0$ 对应的就是之前的确定性 flow,所有轨迹光滑地收敛到原点;随着 $\sigma$ 增大,轨迹变得越来越”混乱”,但最终会收敛到高斯分布 $\mathcal{N}(0, \frac{\sigma^2}{2\theta})$。
数值求解 SDE 的数值求解用的是 Euler-Maruyama Method,和 ODE 的 Euler Method 几乎一模一样,只是多了一个噪声项:
\[X_{t+h} = X_t + h\,u_t(X_t) + \sqrt{h}\,\sigma_t\,\epsilon_t, \quad \epsilon_t \sim \mathcal{N}(0, I_d)\]Diffusion Model 的定义。 和 Flow Model 一样,Diffusion Model 也是用神经网络来参数化向量场:
\[\mathrm{d}x_t = u_t^{\theta}(x_t)\,\mathrm{d}t + \sigma_t\,\mathrm{d}W_t\]训练完成后,通过 Euler-Maruyama Method 从 $X_0 \sim p_{init}$ 出发模拟 SDE,最终得到 $X_1 \sim p_{data}$。值得注意的是,当 $\sigma_t = 0$ 时,SDE 退化为 ODE,Diffusion Model 就变成了 Flow Model——所以 Flow Model 是 Diffusion Model 的特例。
Euler 求解的实际效果
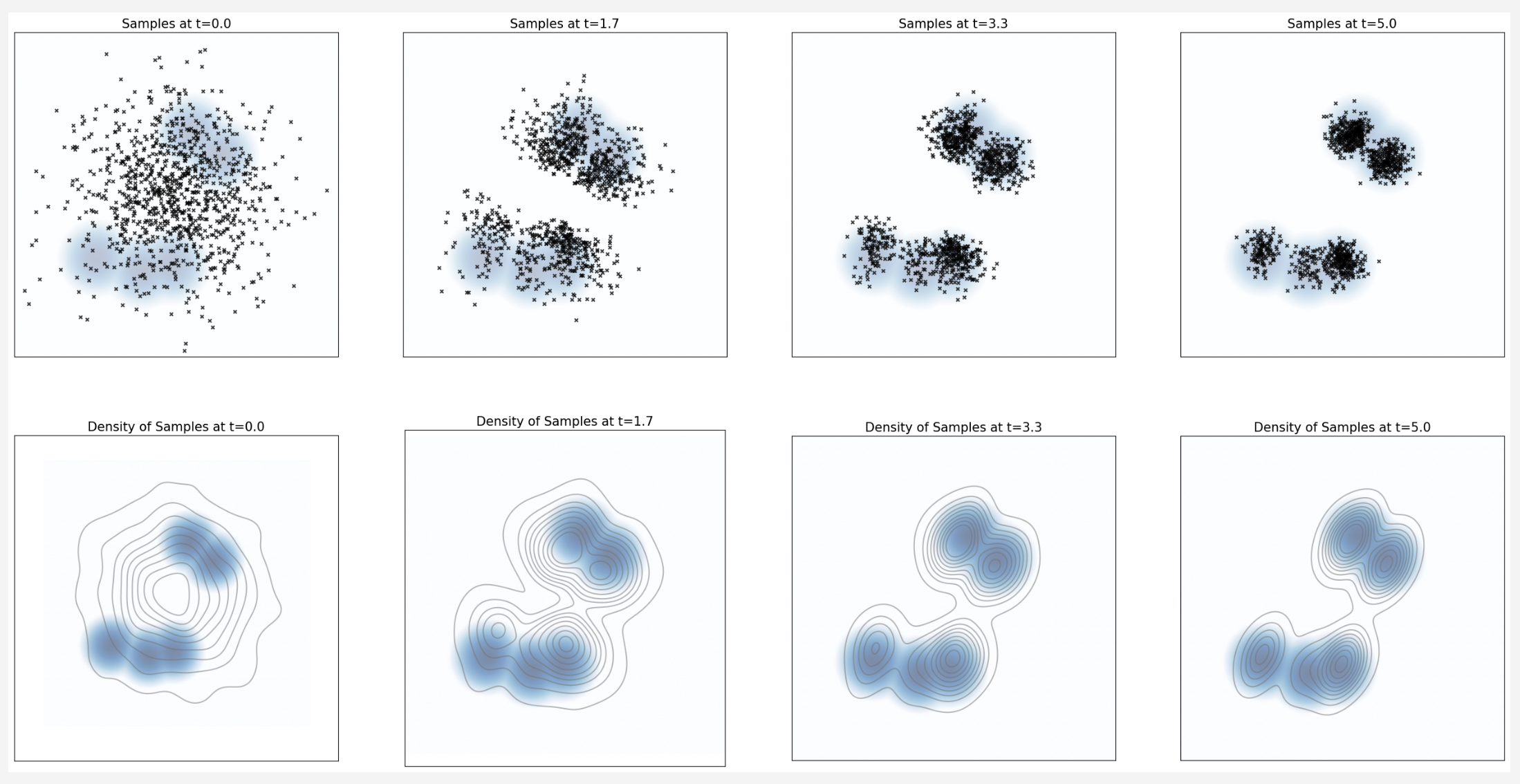
说实话,我在最初读到 Euler Method 的时候,是相当质疑它的求解效果的——这么粗暴的一阶近似真的能用?MIT 6.S184 的 Lab 1 在一个简单的分布上展示了其效果。
在下面这张图里,蓝色背景代表一个目标分布(用混合高斯分布模拟)。因为分布已知,我们可以精确计算所需的一切。黑色的点是通过 Euler 法一步一步迭代得到的采样结果——可以看到效果相当不错。
而在实际的图像生成开源模型中,Euler 也确实是主力求解器。以 Qwen-Image 为例,在 HuggingFace 的 scheduler_config.json 中可以看到它使用的是 FlowMatchEulerDiscreteScheduler——光看名字就知道,这是一个 Flow Matching 模型,采用 Euler 作为求解器。
进一步查看 FlowMatchEulerDiscreteScheduler 的源码,核心的 step 函数做了简化之后本质上就是:
1
prev_sample = sample + dt * model_output
和前面的 Euler 公式简直一模一样。
P.S. 注意到课程上 $x_0$代表的是噪声,而实际上代码里$x_0$代表的图片,为什么公式还能一模一样呢?其实本质上就看 model_output 那里符号的差异。有意思的是,Qwen-Image 直接把模型输出的 noise_pred 喂给 Scheduler;而 Z-Image 则多了一步神奇的 noise_pred = -noise_pred。仔细看发现两边喂给模型的 timestep 含义都一样,唯一的区别就是这个正负号。从这个细微的差异能明显看出,两个模型虽然都出自阿里,但肯定不是一个团队做的。(我到底是 debug 过什么 bug 才会注意到这种无聊的细节啊 lol)
SGLang-Diffusion Pipeline
理解了上面的理论之后,再来看实际的工程实现就清晰多了。以 SGLang-Diffusion 的 pipeline 为例,它定义了一个标准的 text-to-image 流程(考虑到代码变化很快,这里直接贴出来):
1
2
3
4
5
6
7
8
9
10
# prompt -> embedding
self.add_standard_text_encoding_stage()
# 随机初始化 latent,即从高斯分布中采样 X_1 ~ p_init
self.add_standard_latent_preparation_stage()
# 选择 timesteps
self.add_standard_timestep_preparation_stage()
# 通过 Scheduler 反复调用模型进行去噪,即求解 ODE/SDE
self.add_standard_denoising_stage()
# 将 latent 通过 VAE Decoder 转换为最终的图片/视频
self.add_standard_decoding_stage()
对照前面的理论,每个阶段的含义都很直接:latent_preparation 就是从 $p_{init}$ 中采样起点;timestep_preparation 决定了数值求解的步长(以及精度);denoising 就是前面反复讨论的 Euler 迭代过程——反复调用神经网络 $u_t^\theta$,沿着向量场一步步把噪声变成数据。最后的 decoding 则是因为如今的模型通常不在像素空间直接操作,而是在一个低维的 latent space 中完成生成,再通过 VAE Decoder 映射回像素空间。
把整条 pipeline 和理论对应起来看:
\[z \sim \mathcal{N}(0, I) \xrightarrow{\text{denoising (ODE/SDE)}} x_0^{\text{latent}} \xrightarrow{\text{VAE Decode}} x_0^{\text{pixel}}\]写到这里,从”Generation as Sampling”的抽象概念,到 Flow/Diffusion Model 的数学建模,再到 Euler 求解器的工程实现,最后落到一个实际的 pipeline——整条链路就串起来了。后续的文章会继续深入 training 的部分,看看 flow matching 和 score matching 的训练目标是怎么推导出来的,以及它们在代码里长什么样。
